By: Nishtha Gupta
The field of artificial intelligence has seen remarkable advances in recent years, with language models achieving human-parity performance on many natural language processing tasks. However, a new frontier is emerging with the development of multimodal large language models (LLMs) that can process and generate not just text, but also images, audio, and other modalities. These AI systems have the potential to revolutionize human-computer interaction, enabling seamless multimodal communication and unlocking new applications across industries. From automating multimedia content creation to enhancing accessibility through audio- visual AI assistants, multimodal LLMs represent a paradigm shift in how we conceive of and interact with intelligent systems. As this technology continues to evolve, it promises to reshape our digital experiences and push the boundaries of what is possible with AI.
Unlike traditional language models that primarily operate on textual inputs, multimodal LLMs can understand and generate content based on a richer set of input sources, enabling them to capture a more comprehensive understanding of the world. This integration of modalities allows for more nuanced and contextually aware interactions, making multimodal LLMs particularly valuable in applications that require a deeper understanding of multimodal data, such as image captioning, video analysis, virtual assistants, and content generation.
Architecture
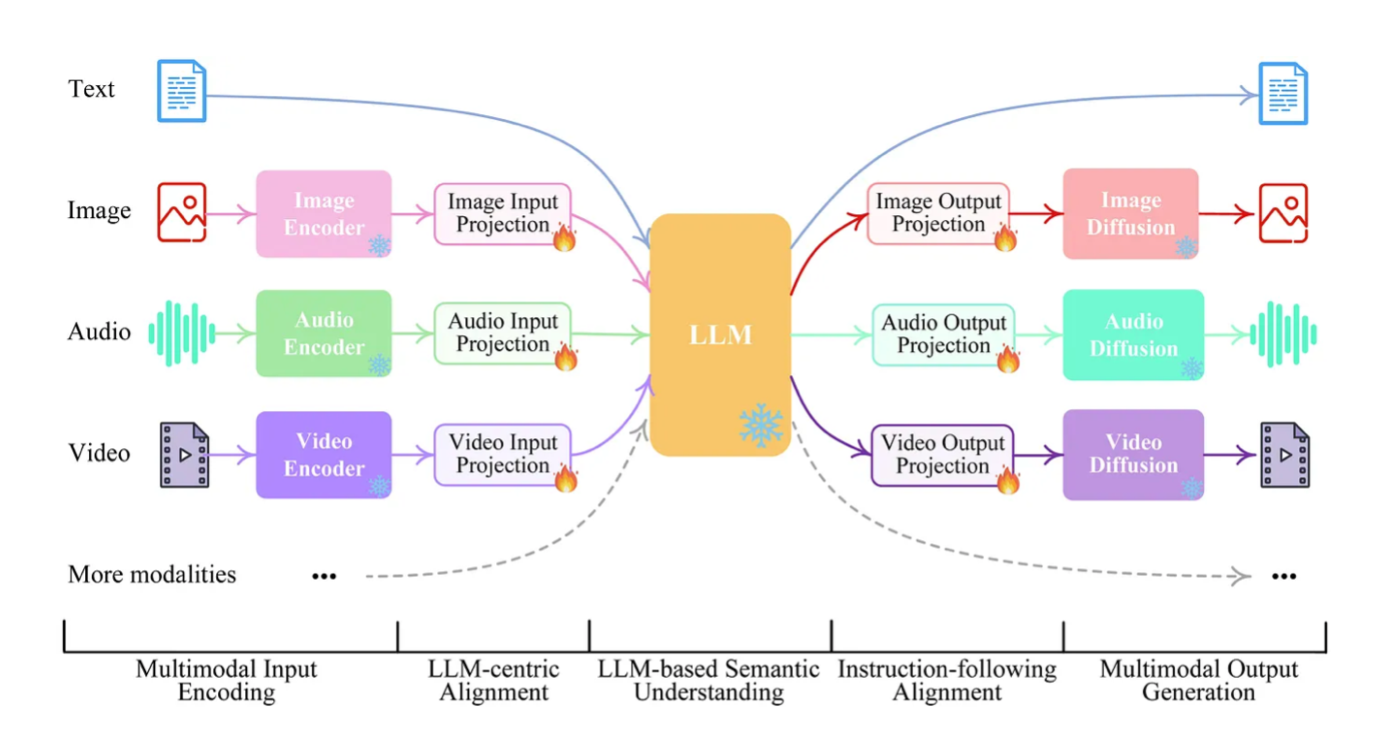
Multimodal LLMs have five main components:
- Modality encoders: Encode inputs like images into a representation the LLM understands.
- LLM backbone: Provides core language abilities, often a pretrained model like GPT-3.
- Modality generators: Convert LLM outputs into different modalities like images, critical for multimodal generation.
- Input projectors: Integrate and align encoded inputs for the LLM.
- Output projectors: Convert LLM outputs into appropriate multimodal formats.
At the core of a multimodal LLM lies a fusion mechanism that integrates information from different modalities. This fusion can occur at different levels of the model architecture, ranging from early fusion, where modalities are combined at the input level, to late fusion, where they are combined at higher layers in the model. Early fusion involves concatenating or combining representations from different modalities before feeding them into the model, whereas late fusion involves merging representations learned separately for each modality at later stages of processing. Additionally, attention mechanisms are often employed to dynamically weigh the importance of different modalities at each step of processing, allowing the model to focus on relevant information while filtering out noise.
Furthermore, multimodal LLMs typically leverage pretraining on large-scale datasets to learn representations that capture the joint distribution of multiple modalities. This pretraining process involves training the model on a diverse range of multimodal data, such as image-text pairs or audio-text pairs, to learn shared representations that effectively capture the relationships between modalities. By pretraining on multimodal data, the model can acquire a broad understanding of the correlations between different modalities, which can then be fine-tuned on specific downstream tasks.
Overall, the architecture of a multimodal LLM reflects a complex interplay of components designed to seamlessly integrate information from multiple modalities and leverage shared representations to achieve a deeper understanding of multimodal data. As research in this area continues to advance, we can expect further innovations in multimodal LLM architectures to enable even more sophisticated multimodal understanding and generation capabilities.
Existing Multimodal LLMs
- KOSMOS -1
Microsoft created Kosmos-1, a multimodal large language model (MLLM) that can understand generic modalities, learn in context, and obey commands. Kosmos-1 is trained from scratch using web-scale multimodal corpora, comprising text data, image-caption pairs, and interleaved text and images. They test different configurations, such as few-shot, multimodal, and zero-shot chain of thought prompting, on a variety of tasks without any fine-tuning or gradient updates.
Kosmos-1 processes various kinds of sequential data using a general-purpose interface based on the transformer architecture. Text and additional modalities are encoded by the model using a single embedding module. The primary LLM is a conventional transformer decoder that has been improved for long-context modelling and training stability. Kosmos-1 is significantly smaller than other LLMs and visual reasoning models, with a size of just 1.6 billion parameters.
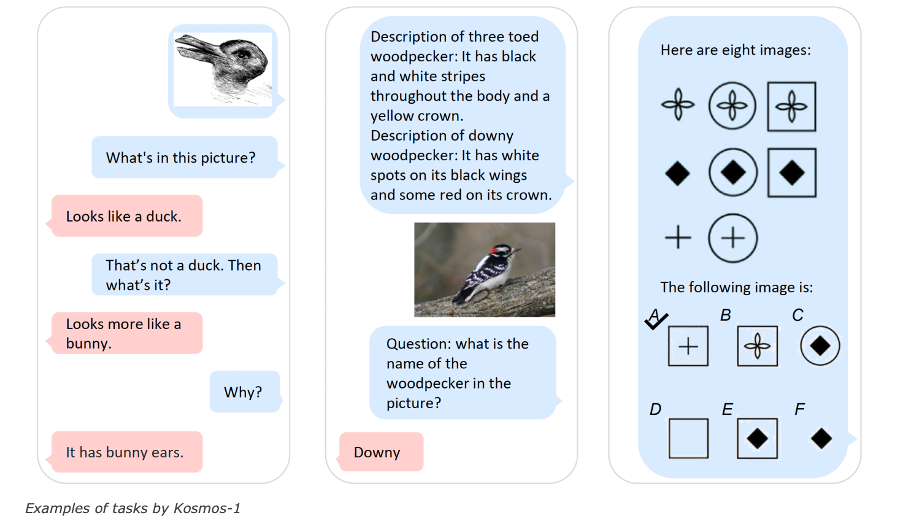
Using Raven IQ tests, one of the intriguing discoveries is non-verbal reasoning, in which the LLM predicts the next image in a series. These kinds of tasks demand the ability to think and abstract. Accuracy when answers are chosen at random is 17%. When Kosmos-1 was trained, it saw no instances of Raven and reached an accuracy of 22–26%. Although a considerable increase, this performance is still far behind that of a person. By aligning perception with language models, Kosmos-1 demonstrates the potential of MLLMs to perform zero-shot nonverbal reasoning, according to the researchers.
- NExT-GPT
NExt-GPT is built on top of existing pre-trained LLM, multimodal encoders, and state- of-the-art diffusion models, with sufficient end-to-end fine-tuning. This state-of-the- art multimodal LLM can handle four different kinds of inputs: text, video, audio, and images. The NExt-GPT model is composed of three main components:
- Create encoders to take input from several modalities and convert it into a language-like format that the LLM can handle.
- Utilize the data for semantic comprehension and reasoning by incorporating an additional modality signal, while leveraging the open-source LLM as the core.
- Provide distinct encoders with a multimodal signal, and then output the result to the relevant modalities.
- FLAMINGO
This multimodal LLM, called Flamingo, was introduced in 2022. Flamingo works by transforming videos or images into embeddings (lists of numbers) via the vision encoder. These embeddings vary in size based on the input image dimensions or video durations; hence, an additional component known as the Perceiver Resampler transforms these embeddings into a standard fixed length.
Text and the fixed-length vision embeddings from the Perceiver Resampler are fed into the language model. Several "cross-attention" blocks employ the visual embeddings to teach them the importance of certain elements of the embedding in relation to the text at hand.
Flamingo uses CLIP, which stands for Contrastive Language-Image Pre-training, in its pre-training stage. CLIP is a training methodology that produces separate vision and text models with powerful downstream capabilities.
To give Flamingo models the ability to learn in-context few-shots, it is essential that they be trained on extensive multimodal web datasets with freely interleaved text and images. Several comprehensive assessments are conducted on these models, investigating and quantifying their capacity to quickly adjust to a range of picture and video tasks. These assessments comprise captioning tests, which assess the model's capacity to describe a scene or an event; open-ended tasks like visual question-answering, in which the model is given a prompt and must respond; and closed-ended tasks like multiple-choice visual question-answering. By providing task-specific examples to the Flamingo model, it is possible to attain a new state of the art in few-shot learning for any task falling anywhere along this range. On numerous benchmarks, Flamingo outperforms models fine-tuned on thousands of times more task-specific data.

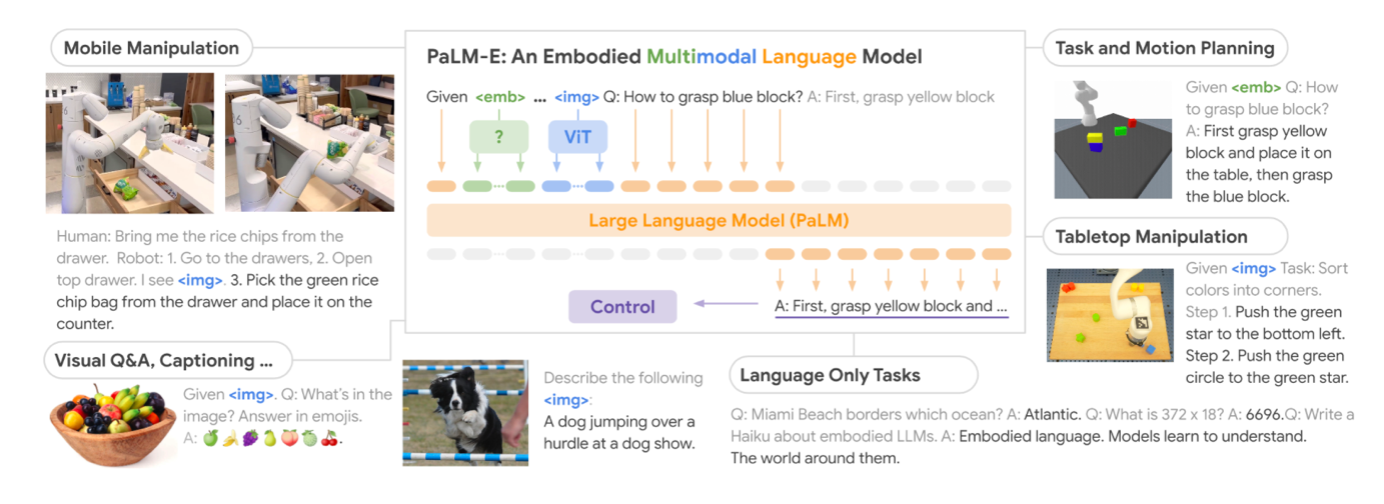
- PaLM-E
Researchers at TU Berlin and Google created the "embodied multimodal language model," or PaLM-E. The paper defines embodied LLM as enabling "continuous inputs from sensor modalities of an embodied agent and thereby enable the language model itself to make more grounded inferences for sequential decision making in the real world." For instance, the model can incorporate sensor data from a robot to respond to inquiries about the outside environment or to execute commands in plain language.
Injecting continuous, embodied observations—such as pictures, state estimations, or other sensor modalities—into a pre-trained language model's language embedding space is the fundamental architectural concept of PaLM-E. To achieve this, the continuous observations are encoded into a series of vectors that have the same dimension as the language token embedding space. Thus, the continuous data is fed into the language model in a manner similar to how language tokens are. Given a prefix or prompt, PaLM-E is a decoder-only LLM that produces textual completions autoregressively.
The model's inputs are multimodal sentences with interleaving text, visual data, and state estimation. The model's output can be a series of textual decisions that can be translated into orders that a robot can follow, or it can be responses to queries in plain text. The paradigm is intended for embodied tasks including planning tasks for mobile robots and manipulating objects robotically. On the other hand, it can also perform non-embodied tasks like producing natural language and responding to visual questions.
By utilizing models developed to encode data from several modalities into the embedding space of the primary LLM, the researchers integrated the pre-trained PaLM model with these models. They put the model to the test on a range of robot activities, such as motion and task planning. PaLM-E showed an ability to perform new tasks.
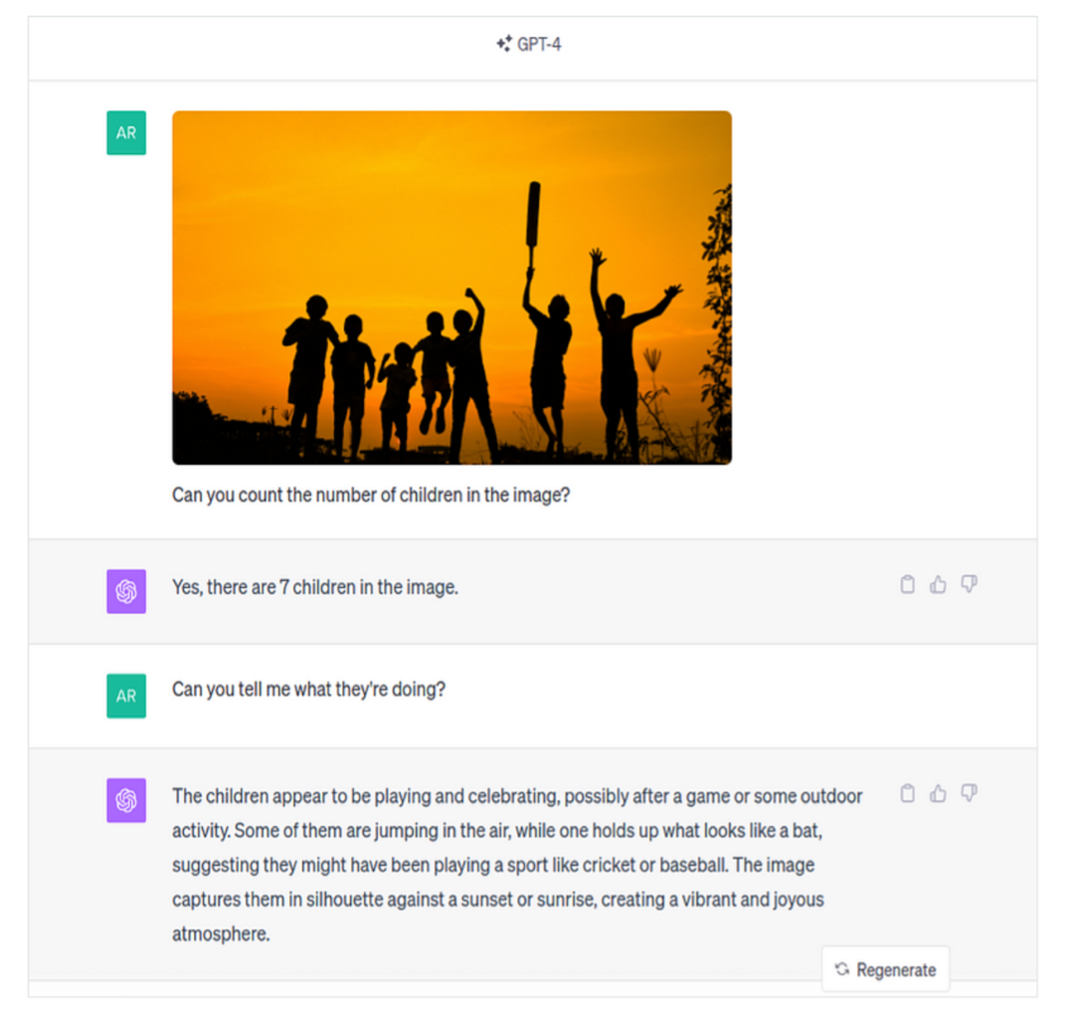
- GPT4-V
A user can upload a picture to GPT-4 Vision (GPT-4V), a multimodal model, and A user can upload a picture to GPT-4 Vision (GPT-4V), a multimodal model, and have a discussion with the model. Questions or prompts that instruct the model to carry out activities based on the input given in the form of an image could be included in the chat.
Building on the existing characteristics of GPT-4, the GPT-4V model provides visual analysis in addition to the text interaction elements. We have provided an approachable overview of the OpenAI API that will assist you in keeping up with the advancements made before the GPT-4V model was made public.
Key capabilities of this model are:
- Visual inputs: The key feature of the newly released GPT-4 Vision is that it can now accept visual content such as photographs, screenshots, and documents and perform a variety of tasks.
- Object detection and analysis: The model can identify and provide information about objects within images.
- Data analysis: GPT-4 Vision is proficient in interpreting and analyzing data presented in visual formats such as graphs, charts, and other data visualizations.
- Text deciphering: The model is able to read and interpret handwritten notes and text within images.
- Qwen LM
Qwen is the name of the extensive family of language models that Alibaba Cloud has constructed. This group regularly releases large language models (LLM), large multimodal models (LMM), and other AGI-related projects. Now, Qwen is available as a massive language model series with 110 billion parameters (compared to 0.5 billion). Additionally, Qwen-VL and Qwen-Audio, which are Qwen-based visual and audio language models, respectively, have been released.
Fundamentally, the multimodal AI under consideration depends on the following technological foundations:
- OpenSearch (LLM-Based Conversational Search Edition): Utilizes large-scale models and vector retrieval to customize Q&A systems to particular company needs.
- Qwen-Audio: Transforms various audio inputs into usable text.
- Qwen-Agent: Coordinates intelligent agents that perform complex tasks and follow commands.
- Qwen-VL: Provides exceptionally accurate image analysis that extracts text and subtle information from photos.
- Model Studio: Brings our multimodal ecosystem to life with this one-stop AI creation platform.
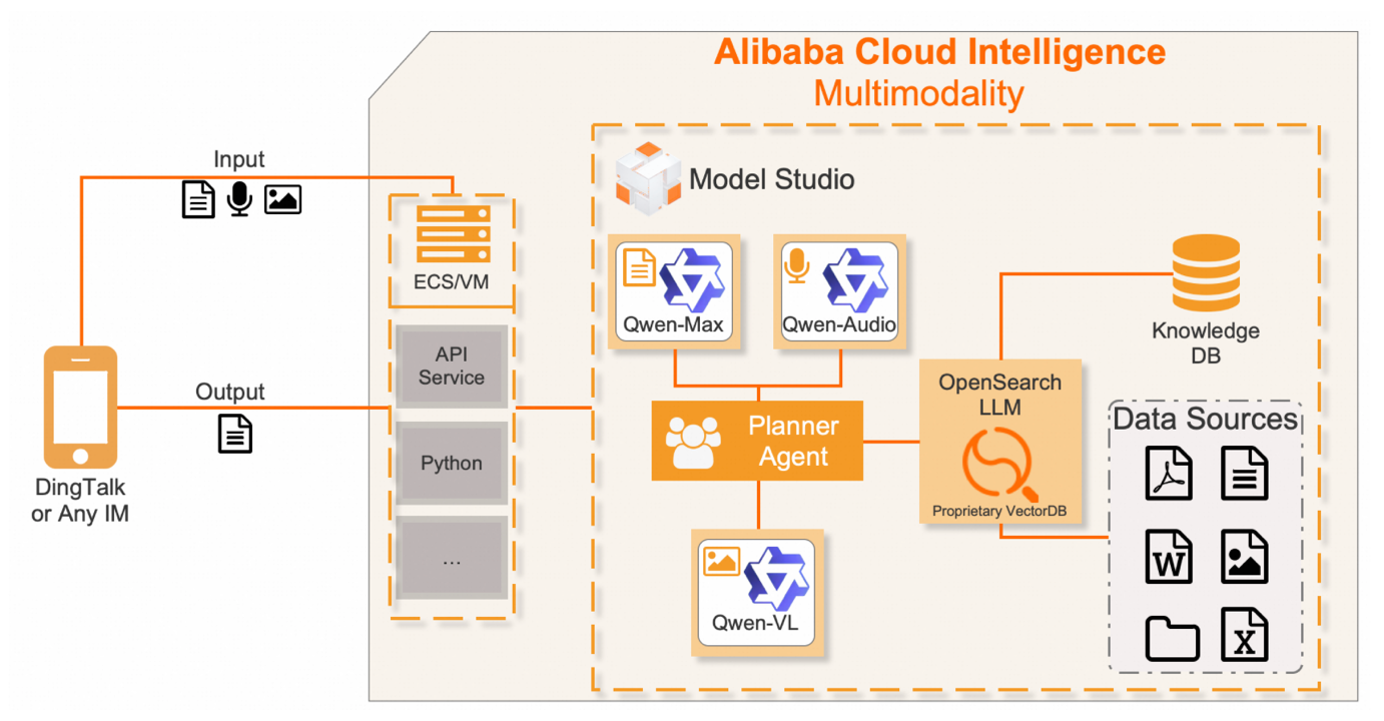
A planner agent, which manages each solution and the reasoning behind it, was employed. All solutions are integrated into a single generative AI pipeline using Model Studio's Planner Agent. Additionally, using Python, an API will be developed and connected to DingTalk Instant Messenger (IM) or any other instant messaging platform of your choice, ready for deployment on Alibaba Cloud's Elastic Computing Service (ECS).

- InternLM
InternLM is developed by Shanghai AI Laboratory. It’s an open-source lightweight training framework that aims to enable model pre-training without requiring many dependencies. It achieves impressive speed optimizations with a single codebase that supports both fine-tuning on a single GPU and pre-training on large-scale clusters with thousands of GPUs. During training on 1024 GPUs, InternLM attains an acceleration efficiency of about 90%. The several models developed by them include:
- InternLM: a series of multi-lingual foundation models and chat models.
- InternLM-Math: state-of-the-art bilingual math reasoning LLMs.
- InternLM-XComposer: a vision-language large model (VLLM) based on InternLM for advanced text-image comprehension and composition.
Based on InternLM2-7B, InternLM-XComposer2 is a vision-language large model (VLLM) that excels in free-form text-image creation and comprehension. It has numerous incredible features and uses:
Unstructured Interleaved Text-Image Composition: Using various inputs such as outlines, specific text needs, and reference images, InternLM-XComposer2 can easily produce cohesive and relevant articles with interleaved images, allowing for highly flexible content production.
Accurate Vision-Language Problem-Solving: Using free-form instructions, InternLM-XComposer2 effectively completes a variety of difficult and demanding vision-language Q&A tasks, demonstrating exceptional performance in recognition, perception, detailed captioning, visual reasoning, and other areas.
With fantastic performance based on InternLM2-7B, InternLM-XComposer2 not only outperforms current open-source multimodal models in 13 benchmarks, but in 6 benchmarks, it even matches or exceeds GPT-4V and Gemini Pro.
To talk about the architecture of InternLM, it consists of two critical design elements:
- Partial LoRa which is a plug-in module designed to align embedding space between visual and text tokens. They have used P-LoRA with the Vision Encoder, and while having fewer trainable parameters than with earlier approaches, it is sufficient for effective parameter adjustment.
- High-quality and Diverse Data Foundation which basically means that they prepare high-quality, diverse data for pretraining and fine-tuning models.
Wrapping Up
Multimodal large language models (LLMs) represent advancements in natural language processing, enabling machines to understand and generate content across multiple modalities such as text, images, audio, and more. Throughout this blog, we've explored the architecture, capabilities, and potential applications of multimodal LLMs.
The future scope of multimodal models is incredibly promising, spanning numerous domains and applications. By combining information from diverse modalities such as text, image, audio, and video, multimodal models offer the potential to deepen our understanding of content, enhance human-computer interaction, and revolutionize content creation and generation processes. These models facilitate tasks like cross-modal retrieval, personalized recommendation systems, and context-aware services, enabling more intuitive and adaptive user experiences.
Furthermore, multimodal models hold the key to addressing challenges related to robustness, generalization, and ethical AI by leveraging complementary information from different modalities and mitigating biases inherent in individual data sources.
As research in multimodal learning continues to advance, we can anticipate these models playing a pivotal role in shaping the future of AI across diverse industries and domains.




