Multimodal AI: The Convergence of Vision, Language, and Beyond
INTRODUCTION
In today’s rapidly evolving technological landscape, AI is undergoing a transformative shift—from unimodal systems that process only text or images, to multimodal AI that integrates diverse data types such as text, images, video, audio, and even sensory inputs into a single, cohesive framework. This is not merely a step forward; it is a transformative shift that is opening up new possibilities in human-computer interaction, scientific breakthroughs, and industrial advancements.
Driven by groundbreaking advancements in transformer architectures, vision-language models (VLMs), and foundation models, multimodal AI is elevating the capabilities of traditional systems by enhancing understanding, reasoning, and generation. Whether it’s deciphering complex medical images, enabling autonomous vehicles to understand and react to their surroundings, or making virtual assistants more intuitive, these models are redefining how machines interpret and interact with the world.
This blog delves into the core enabling technologies behind multimodal AI, exploring how advanced components—ranging from Large Language Models and Vision Transformers to audio processors and diffusion models—come together to create a system that truly understand multifaceted data. We will also discuss real-world business applications and customer use cases that highlight the impact of this transformative technology, as well as the challenges and ethical considerations that should be considered in this new world.
Join us as we embark on an exciting adventure where vision, language, and beyond meet, paving the way for the next generation of intelligent systems.
What are Multi Modal LLMs (MLLMs)?
Multimodal Large Language Models (MLLMs) represent a significant advancement in AI by processing and generating multiple data types—text, images, audio, video, and sensor inputs—within a unified framework. This enables them to perform complex, real-world tasks that traditional unimodal models struggle with.
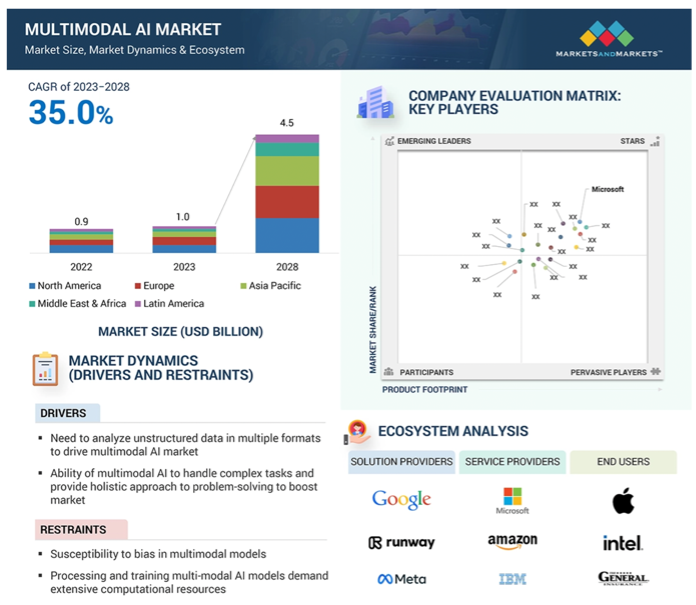
The global multimodal AI market is valued at USD 1.0 billion in 2023 and is estimated to reach USD 4.5 billion by 2028, registering a CAGR of 35.0% during the forecast period.
How Multimodal LLMs Differ from Traditional LLMs
Traditional or Unimodal LLMs specialize in processing only a single type of data (text, images, or audio). In contrast, MLLMs integrate multiple modalities, allowing for richer contextual understanding and more sophisticated applications.
| Aspect | Traditional (Unimodal) LLMs | Multimodal LLMs (MLLMs) |
|---|---|---|
| Data Input | Processes only one modality (text, image, or audio) | Handles multiple data types (text, images, video, and speech) |
| Contextual Understanding | Limited by single data type | Deeper, more holistic insights by combining modalities |
| Interaction Capabilities | Restricted to single-medium interactions | Enables cross-modal tasks like visual Q&A, video summarization, and speech-to-text reasoning |
| Architecture | Uses a single encoder-decoder model | Combines multiple encoders and fusion modules to process diverse inputs |
For instance, while a traditional text-based LLM can generate a description of an image from text prompts, an MLLM like GPT-4V can analyze an image directly and provide detailed insights, enhancing real-world applications in healthcare, robotics, and autonomous systems.
Architectural Components of MLLMs:
- Multimodal Input Encoders : These specialized modules process different data types—text
encoders handle textual data, vision encoders process images and videos, and audio encoders
manage sound inputs.
- Text Encoder (GPT, BERT) for text understanding
- Vision Encoder (ViT, ResNet) for image/video processing
- Audio Encoder (HuBERT, Whisper) for speech and sound interpretation
- Feature Fusion Mechanism : This component integrates information from various modalities, aligning them into a cohesive representation to facilitate comprehensive understanding.
- Multimodal Output Decoder : After fusion, the decoder generates appropriate outputs, which could be text, images, or audio, depending on the application.
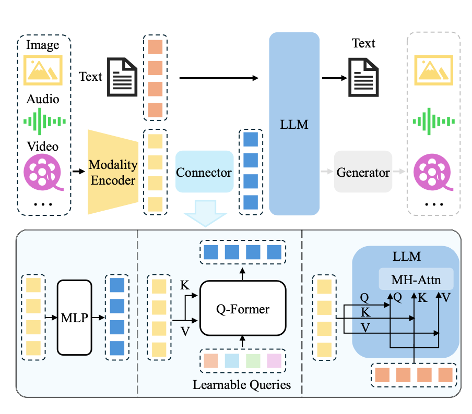
An illustration of typical MLLM architecture. It includes an encoder, a connector, and a LLM. An optional generator can be attached to the LLM to generate more modalities besides text. The encoder takes in images, audios or videos and outputs features, which are processed by the connector so that the LLM can better understand.
By merging multiple data sources into a single framework, MLLMs enable groundbreaking applications in healthcare, creative AI, customer interactions, and automation, marking the next phase in AI evolution.
How does Multi Modal LLM work : A Deep Dive into Their Functionality
Their working mechanism involves three key components: multimodal input encoders, feature fusion mechanisms, and multimodal output decoders, allowing them to understand and generate diverse data output.
1. Multimodal Input Encoders: Processing Diverse Data
The first step in MLLMs is converting raw data into structured representations that the model can process:
- Text Encoding: Uses models like GPT, BERT, and T5 to convert text into semantic embeddings.
- Image Processing: Vision models such as Vision Transformers (ViT), ResNet, and CLIP extract key visual features.
- Audio Analysis: Models like HuBERT, Whisper, and BEATs process speech and sound for context and intent recognition.
- Video Understanding: Frame-based processing with video transformers captures both temporal and spatial information.
2. Feature Fusion: Integrating Multiple Modalities
Once encoded, the Feature Fusion Mechanism integrates multimodal data to form a unified representation, enabling reasoning and decision-making:
- Early Fusion: Combines raw multimodal inputs (e.g., text and images processed together from the start), allowing the system to learn from the combined data.
- Intermediate Fusion: Encoded features from each modality are processed separately and later combined using attention-based techniques, such as Q-Formers.
- Late Fusion: Each modality is processed independently, and their outputs are merged at the final stage.
- Joint Fusion: A combination of the above methods, ensuring optimal multimodal representation.
Cross-modal attention mechanisms further refine how information is integrated, ensuring richer contextual awareness across modalities.
3. Multimodal Output Decoders: Generating Coherent Responses
After fusion, the decoder converts representations into meaningful outputs:
- Text Generation: Used for image captioning, video summarization, and conversational AI.
- Visual Outputs: Models like DALL-E and Stable Diffusion generate realistic images from text descriptions.
- Speech and Audio Synthesis: AI-powered assistants convert text and images into spoken language
This process enables MLLMs to perform complex tasks that require understanding and generating multiple types of data, such as describing images, answering questions about videos, or creating content that combines text and visuals.
Illustrative Example: Visual Question Answering
Consider a scenario where an MLLM is asked to answer questions about an image:
- Image Encoding: The model processes the image to extract visual features.
- Question Encoding: The textual question is transformed into a semantic representation.
- Feature Fusion: The model aligns and integrates the visual and textual features to understand the context.
- Answer Generation: Based on the fused representation, the model generates a relevant textual answer.
This workflow showcases the model's ability to seamlessly integrate and process information from different modalities to provide coherent and contextually appropriate responses.
Types of Multi Modal Models
-
Meta AI's ImageBind
ImageBind by Meta AI is a multimodal model that integrates six data modalities—text, image/video, audio, depth, thermal, and inertial measurement units (IMUs). This comprehensive approach allows the model to create more immersive and contextually rich outputs, paving the way for advanced applications in virtual reality, augmented reality, and beyond.
-
NExT-GPT
NExT-GPT is an innovative multimodal large language model capable of accepting and generating content in various combinations of text, images, videos, and audio. By connecting a language model with multimodal adapters and diffusion decoders, NExT-GPT enables any-to-any multimodal content generation, showcasing the potential for more human-like AI interactions.
-
OpenAI's GPT-4 Vision (GPT-4V)
An enhancement of the original GPT-4, GPT-4V incorporates the ability to process both text and images. This allows the model to generate visual content based on textual descriptions and understand images to produce corresponding textual narratives. Such capabilities enable more dynamic and interactive AI applications, including advanced content creation and improved user interactions.
-
Google's Gemini
Google's Gemini is a multimodal model designed to handle various data types within a unified architecture. It can understand and generate content across different modalities, such as text, images, and more. For example, Gemini can receive a photo of a plate of cookies and generate a written recipe as a response, and vice versa. This flexibility enhances the model's applicability in diverse scenarios, from creative content generation to complex problem-solving.
-
CLIP (Contrastive Language–Image Pretraining)
Developed by OpenAI, CLIP learns visual concepts from natural language descriptions, enabling it to understand images and text jointly. This allows for tasks like zero-shot image classification and image-to-text retrieval without task-specific training.
-
LLaVA (Large Language and Vision Assistant)
LLaVA integrates visual information into language models, enabling it to process and generate both text and images. This multimodal capability enhances tasks like visual question answering and image captioning.
Multi Modal Models : Use Cases
1. Integrated Customer Support & Personalized Recommendations
Multimodal AI enhances customer interactions by understanding and processing multiple inputs like text, images, and voice to offer better recommendations and responses.
- Analyses customer queries, product images, and purchase history to provide real-time recommendations.
- Improves customer satisfaction by making product suggestions highly relevant.
- Businesses benefit from increased conversion rates and better engagement.
2. Enhanced Fraud Detection & Risk Management
In finance, e-commerce, and betting industries, fraud detection is critical. Multimodal AI strengthens security by analyzing diverse data sources.
- Processes transaction logs (numerical data), chat records (text), and identification images (visual data) to detect anomalies.
- Reduces fraudulent activities and improves security measures for businesses.
- Protects customers from unauthorized transactions and financial losses.
3. E-Commerce & Retail
Retailers leverage multimodal AI to provide more immersive and personalized shopping experiences.
- Analyses product images, search queries, and customer reviews to optimize product discovery.
- Enables personalized recommendations, improving sales and customer satisfaction.
4. Healthcare & Medical Diagnosis
Medical applications of multimodal models help doctors make more accurate and timely diagnoses.
- Integrates medical imaging (X-rays, MRIs) with patient records and clinical notes to improve diagnostic accuracy.
- Assists in disease detection and offers personalized treatment plans.
5. AI-Powered Virtual Assistants
Multimodal AI makes virtual assistants smarter by improving their ability to process voice, text, and visual inputs.
- Enhances AI assistants like Alexa, Siri, and Google Assistant with better contextual understanding.
- Allows users to interact through voice commands, text input, and even image-based queries.
- Improves accessibility and usability across smart devices and applications.
6. Multimodal Search & Content Generation
AI-powered search engines and content creation tools utilize multimodal models to enhance user experience.
- Enables image + text-based searches, making results more relevant and intuitive.
- Supports creative applications like OpenAI’s DALL·E, which generates images from text descriptions.
- Provides better recommendations and enriched content for users.
Challenges:
1. Data Bias:
- MLLMs process diverse data (text, images, audio, video), often inheriting biases from their training datasets.
- Biases can lead to unfair or discriminatory AI outputs, affecting underrepresented groups.
- Ensuring diverse, well-curated datasets is crucial to mitigating bias.
2. Computational Costs:
- Training and deploying MLLMs require immense computing power, increasing costs and energy consumption.
- High resource demands pose scalability challenges for smaller organizations.
- Techniques like model distillation help reduce computational overhead while maintaining performance.
Addressing these issues is essential for developing ethical, unbiased, and sustainable multimodal AI systems.
Conclusion & Future Scope of Multimodal AI
Multimodal AI models have transformed industries by integrating text, images, audio, and video, enabling applications in healthcare, finance, e-commerce, and entertainment. Models like CLIP and DALL- E enhance diagnostics, customer experiences, and creative content generation.
Future Scope:
- Human-Like AI Assistants: Improved real-time language translation and intuitive human- computer interaction.
- Autonomous Systems: Smarter self-driving cars and industrial robotics integrating multiple sensory inputs.
- Creative AI: Personalized storytelling, AI-driven content creation, and digital art generation.
- Healthcare Advancements: AI-driven diagnostics and wearable tech for continuous health monitoring.
- Ethical AI Development: Focus on bias mitigation and responsible AI deployment.
Multimodal AI’s future is promising, with innovations set to revolutionize industries and human-AI collaboration. Ethical considerations, transparency, and responsible development will be key to ensuring fair and impactful AI applications.
References
- https://arxiv.org/abs/2306.13549
- https://arxiv.org/abs/2408.01319
- https://arxiv.org/abs/2409.14993
- https://nyudatascience.medium.com/new-framework-improves-multi-modal-ai-performance-across-diverse-tasks-2e2ef3a4298d
- https://encord.com/blog/top-multimodal-models/
- https://www.globenewswire.com/news-release/2024/11/28/2988730/0/en/Multimodal-AI-Market-Skyrockets-to-10-550-20-Million-by-2031-Dominated-by-Tech-Giants-Aimesoft-Inc-Alphabet-Inc-and-Amazon-Web-Services-Inc-The-Insight-Partners.html
- https://medium.com/@tenyks_blogger/multimodal-large-language-models-mllms-transforming-computer-vision-76d3c5dd267f
- https://www.researchandmarkets.com/reports/5914269/multimodal-ai-market-global-forecast
Written By

Ankit Saran
April 22, 2025



