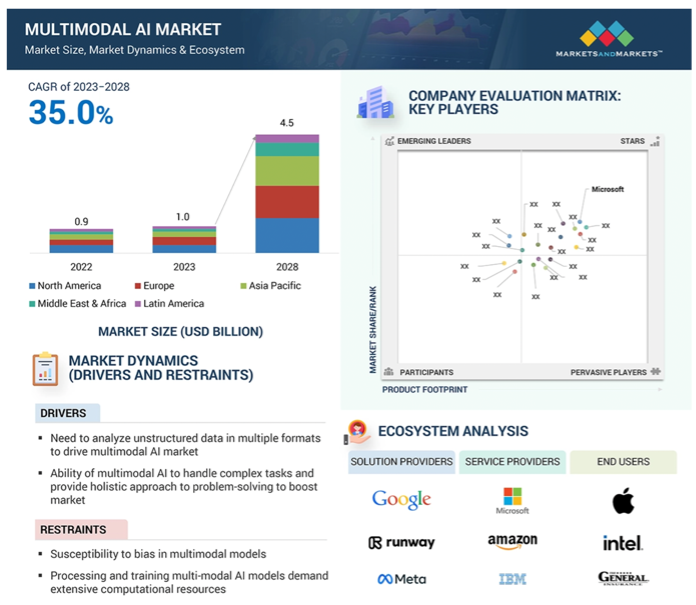
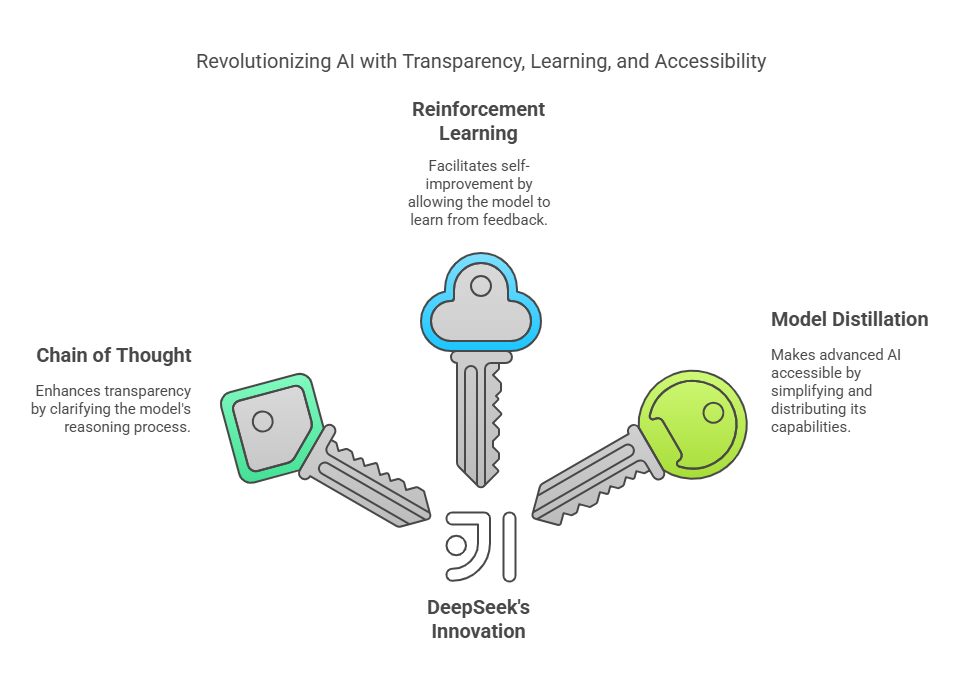
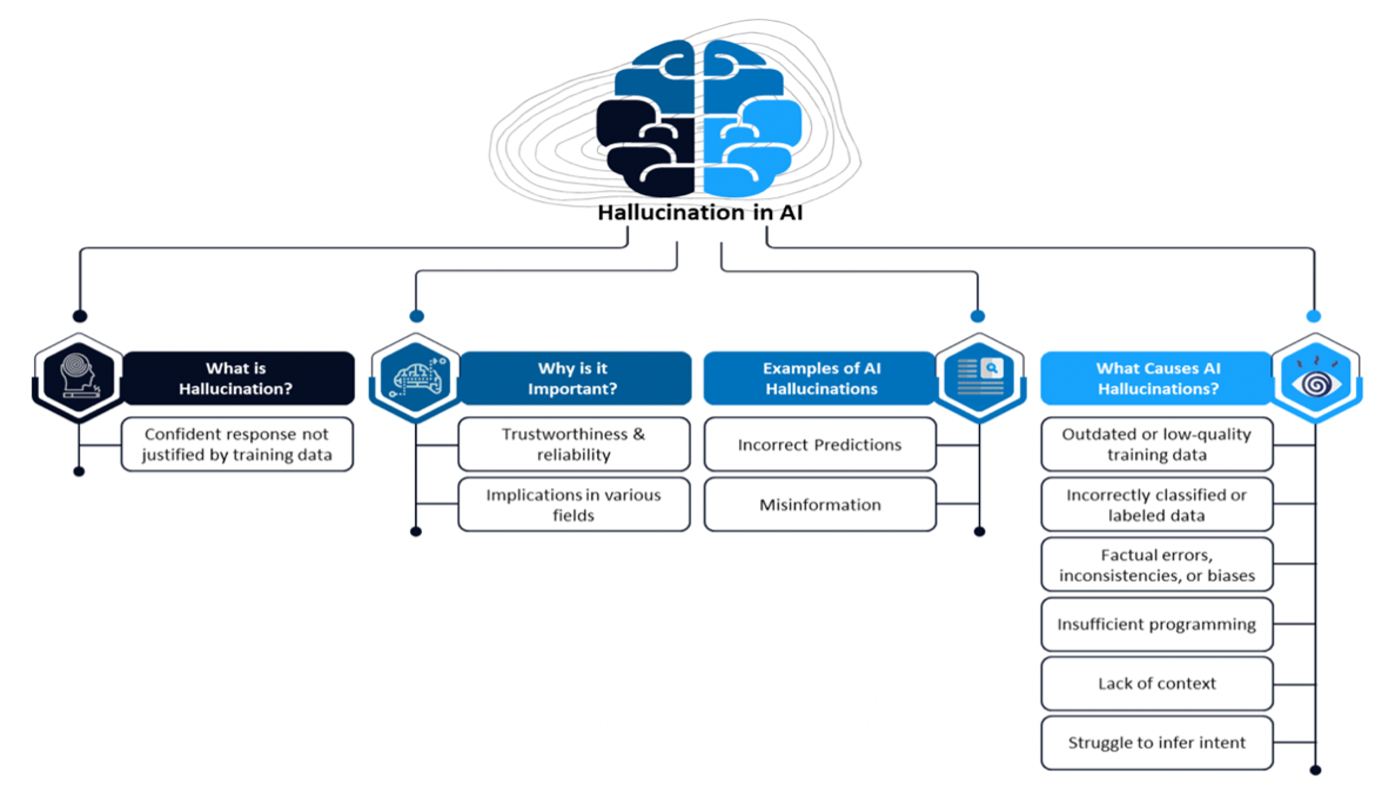
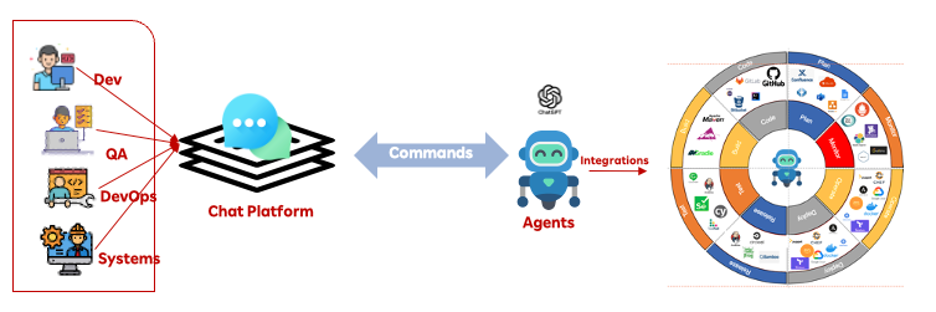
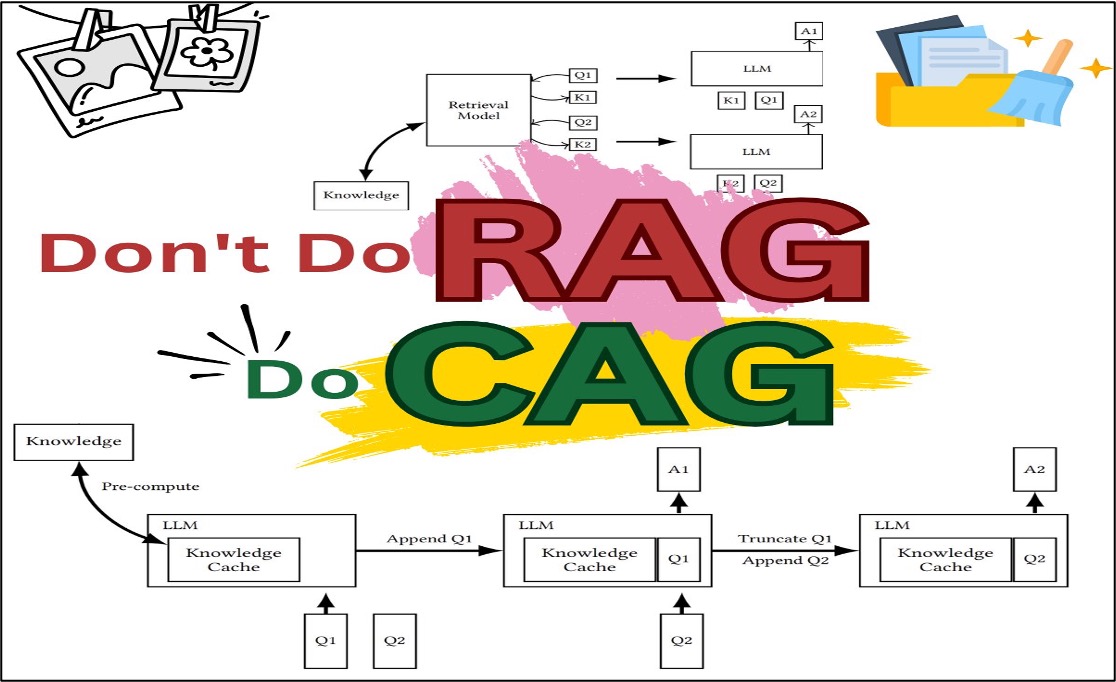
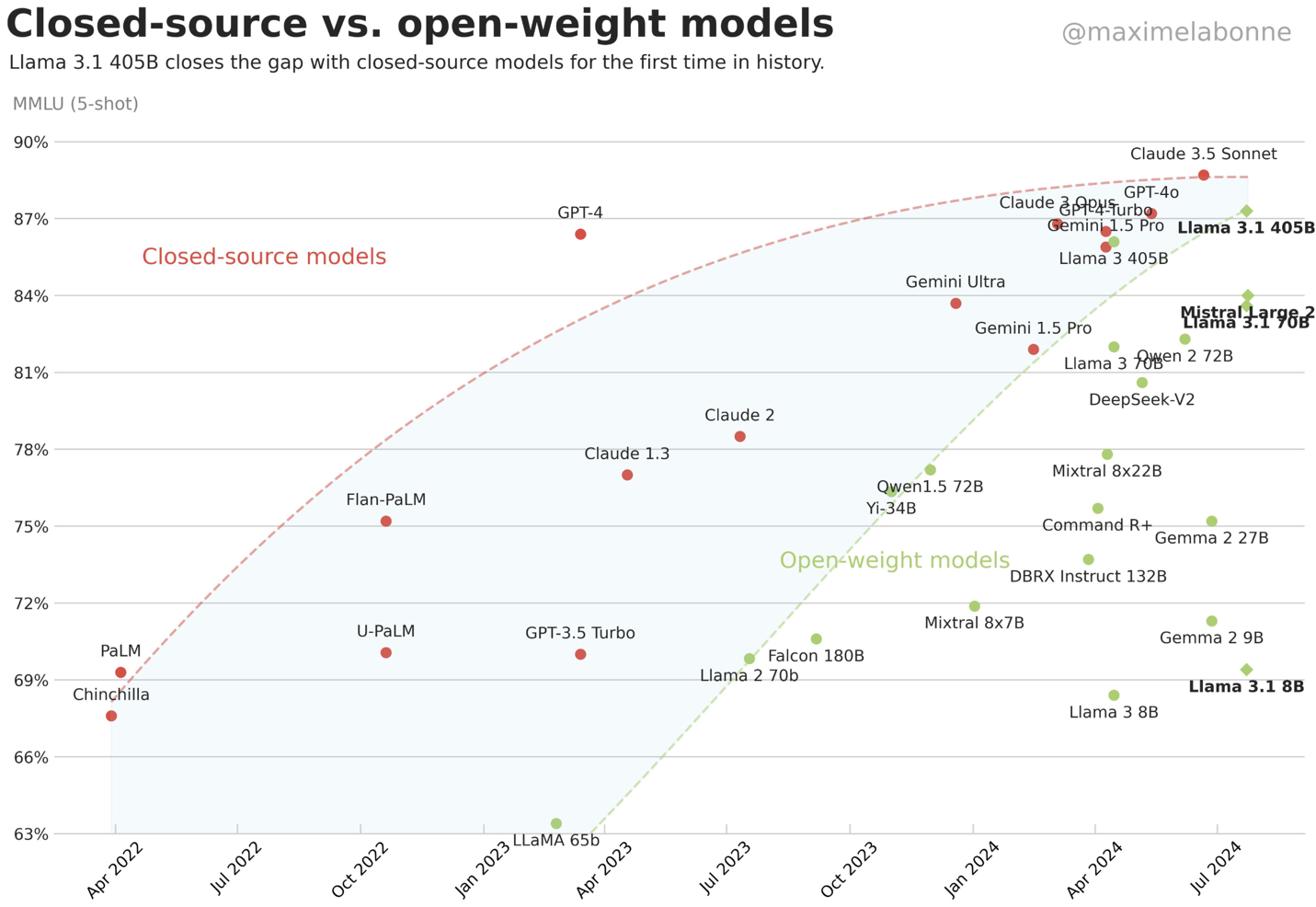
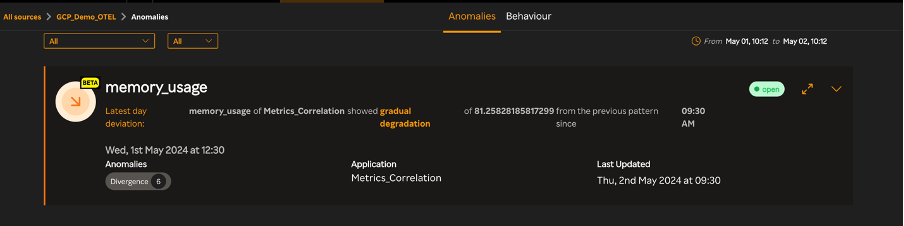
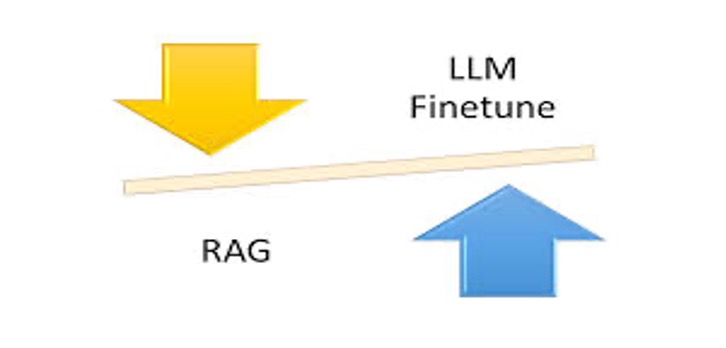
Multimodal AI: The Convergence of Vision, Language, and Beyond
Multimodal AI is transforming artificial intelligence by integrating diverse data types—text,
images, audio, video, and sensory inputs—into unified frameworks, enabling machines to
process and generate richer, more contextual outputs. Unlike traditional unimodal models,
Multimodal Large Language Models (MLLMs) combine multiple modalities, enhancing
understanding, reasoning, and interaction capabilities. These models leverage advanced
architectures, including multimodal input encoders, feature fusion mechanisms, and
multimodal output decoders, to process and integrate data seamlessly.