The Need for Chain of Thought Prompting and Meta Reasoning Based LLM’s
INTRODUCTION
In this ever evolving field of innovation and in the age of Artificial Intelligence , Generative AI has made significant leaps in terms of the impact it has had on the tech community. This sub field of AI , despite seeing exponential development and advancements is still in many ways nascent in it’s lifecycle , with many Large language models failing to perceive and answer logic and reasoning based , mathematics based , highly contextual or layered questions. There was a vacuum for chain of thought based LLM’s to come into the picture in order to systematically solve complex multi step problems, develop a train of thought and come up with more analytical and well thought out answers.
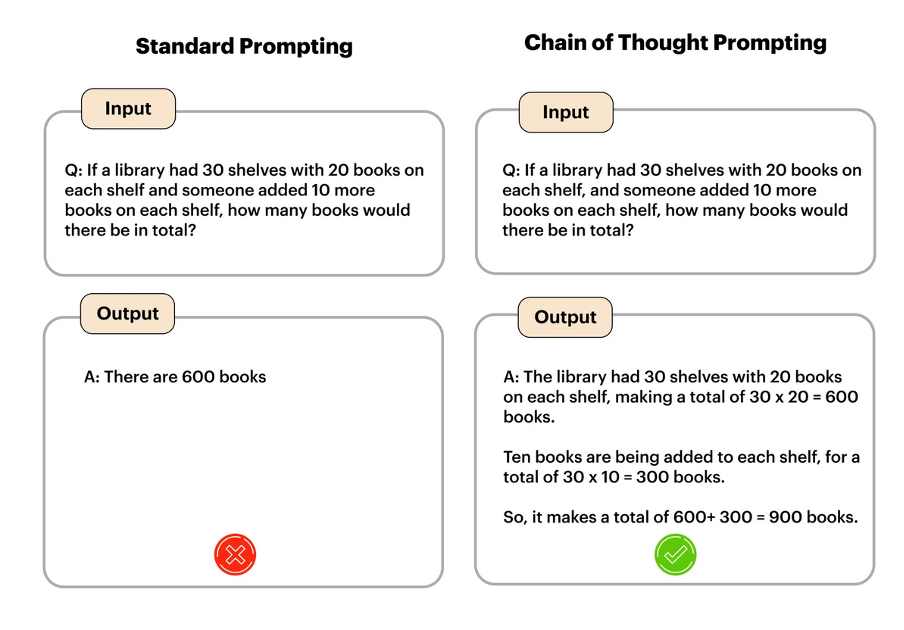
Open AI filled this void by releasing it’s new generation of o1 transformer models having an enhanced reasoning functionality. That is, instead of just providing a response as swiftly as possible and using the basic transformer approach of weights and understanding what word or sequence of words belong together, o1 "thinks" about what the right approach is to solve a problem. The strategy taken by companies like OpenAI and Deepseek for reasoning is based off of chain of thought prompting, where a model reasons step by step through a task in an iterative manner. The AI when solving a problem or answering a question will internally create two or more chain-of-thought instances. The sky is the limit on the exact number of chains we might encourage the AI to internally produce. After devising multiple chains, the AI would attempt to leverage the respective chains and derive a more thought out answer than might otherwise occur when relying on simply one chain alone. Below is a visual example of how chain of thought prompting looks like :-
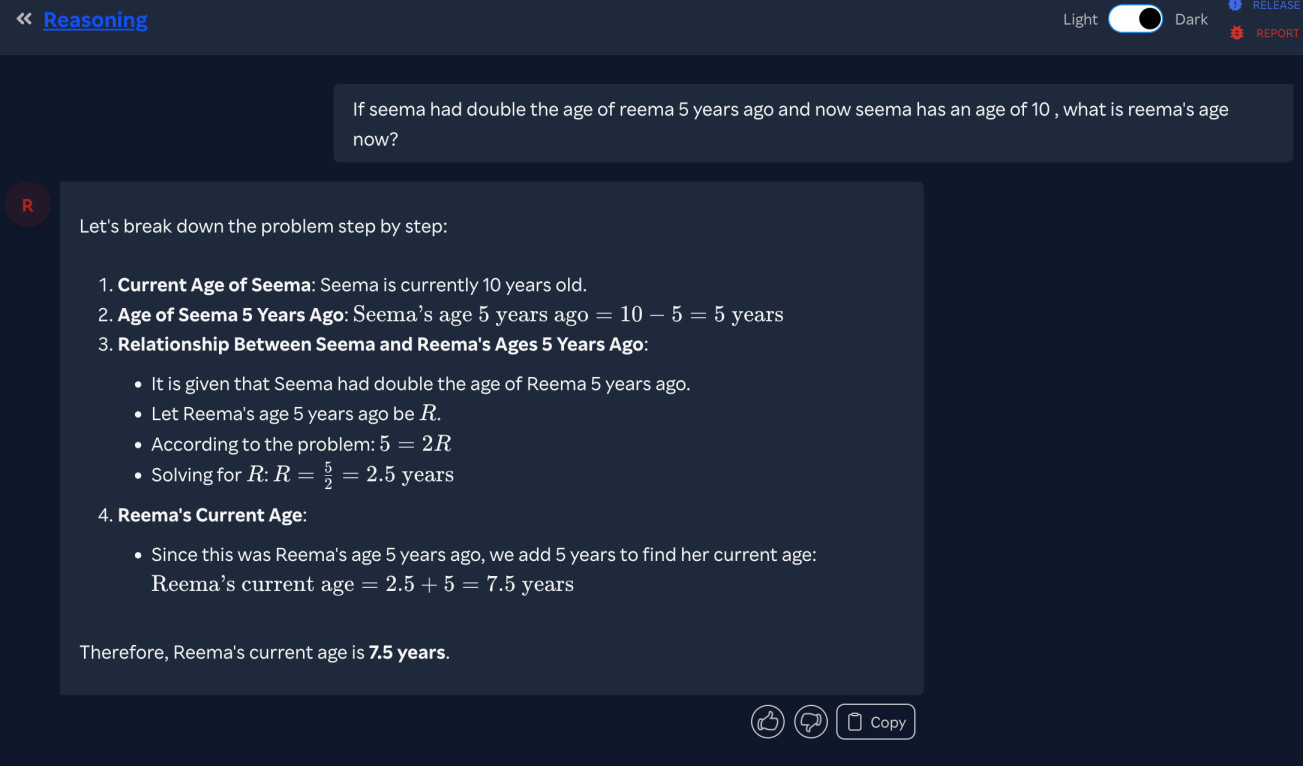
Below Is another example where a sample question was asked to Open Ai’s reasoning model and it gave a step by step solution with necessary explanations and equations:
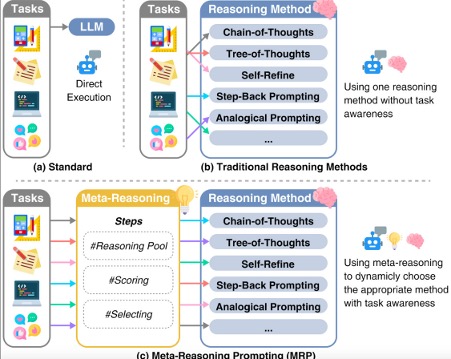
The process of somehow considering and bringing altogether the multiple chains into a coherent result is said to be meta-reasoning. This is known as meta-reasoning because, in a broad sense, the overarching combining function is “reasoning” about the various chain-of-thought reasonings (i.e., reasoning about reasoning). The word “meta” conventionally is used to stipulate that something transcends other items. In this case, we are trying to transcend the multiple chain-of-thought instances and “reason” about them across the board to arrive at a suitable answer. Whether it is or isn’t in the mix, one can bet that AI pioneers and generative AI frontrunners like Alibaba’s Qwen 2.5 , Deepseek’s-V3 model and Open AI’s o1 model for instance are going to be and already are in hot pursuit of this kind of approach. A bevy of questions and mysteries lie within. For example, how many chains should be generated for a given problem that is being solved? There’s a computational cost/benefit trade-off associated with producing chains. How much processing time should be devoted to meta-reasoning? You could nearly endlessly let meta-reasoning try zillions of permutations and combinations of seeking to combine or align multiple chains. If optimized for resources and time , this could very well be the start of a new wave of transformers and a new age of AI. Rakuten has started to explore such models with these models providing a significant boost in accuracy of precision when used in various POC’s across the organization.
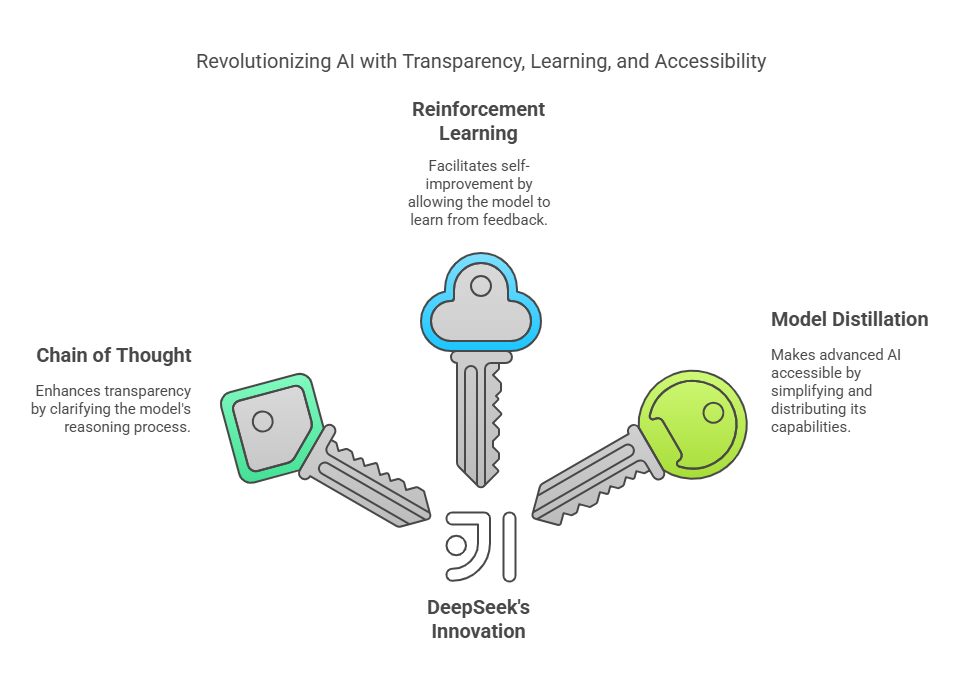
ENABLING TECHNOLOGIES
Reinforcement Learning
-
Despite both Open Ai’s o1 and Deepseek’s V3 models rely on chain of thought prompting , however Deepseek’s architecture is different than the latter.
-
Most AI training looks like educational institutions: show the target model a query, give the right answer to it, and repeat. DeepSeek takes a different approach. It learns more along the lines of how a baby would learn.
-
Babies don’t get instructions. They experiment, fail, adjust, and try again. In turn , getting better and better over time.
-
That’s exactly how one could state in layman’s terms how reinforcement learning works. The model explores different ways to answer a question and picks the one that works best using a reward and exploration based approach.
-
This is also how DeepSeek improves its reasoning capabilities and takes it to the next level.
-
The key theme is Group Relative Policy Optimization (GRPO).
-
Instead of classifying answers as simply correct or incorrect, GRPO compares them to past attempts .If a new answer is better than an old one, the model updates its behaviour.
-
This makes learning more affordable. Instead of needing to accumulate massive amounts of labelled data, the model trains itself by iterating on the mistakes it has made in the past..
-
Given enough training samples and iterations, it might even reach human-level accuracy in reasoning tasks.
Distillation
-
One of the major problems with Deepseek’s model is that they are extremely big. The full version has 671 billion parameters.
-
Running it requires a few thousands of GPUs and that kind of infrastructure , only tech giants can possess making it impractical for most people.
-
Distillation is the solution— taking a giant model and compressing it one that is smaller without losing a lot of performance.
-
The big model generates examples, and the small model learns from them. DeepSeek researchers distilled their model into Llama 3 and Qwen.
-
What was surprising was that the smaller models at times performed better than the original making AI far more responsible. Instead of needing a supercomputer, one can run a powerful model on a single GPU itself.
BUSINESS USE CASES
-
LLM Analyst – Utilizing chain of thought prompting in Large language models allows financial analysts to carefully scrutinize financial reports, assess risks, and eventually extract valuable insights & relevant trends in a stepwise manner leading to more informed and accurate decision making for investments , asset control etc.
-
Education and Tutoring Systems - LLMs in the education sector can utilize the chain of thought prompting to guide students to understand complex topics in subjects such as mathematics , science, and language learning in an organized and systematic manner. They can also allow students to understand the stepwise solution required to solve a problem.
-
Supply Chain Optimization - Talking about supply chain management, the chain of thought prompting supports LLMs in analysing and optimizing the logistics networks by breaking down every component, such as the logistics, inventory levels, transportation routes, and demand forecasts, into manageable parts. This streamlined method results in reduced operation costs, improving performance, and building a strong resilience of the supply chain in multiple industries, such as automobiles, fashion, pharmaceuticals, technology, and more.
CUSTOMER USE CASES
-
Research and Innovation - Researchers leverage the Chain of thought prompting in order to assimilate , analyse, and generate their thoughts to identify patterns or test various hypotheses, which would further help in solving complex problems. This structured and precise approach would accelerate the entire discovery process, ensuring that the tool could be responsible for various scientific and technological breakthroughs.
-
Gen-AI Backed Customer Service Chatbots - Chain-of-thought prompting ensures that complex customer queries are converted into smaller, easily manageable chunks. This would thus allow the best AI chatbots in the market to offer much more accurate and contextual responses to a point where they could in fact replicate humans. By constantly helping the chatbot in every step where it must troubleshoot, Chain of thought prompting promises to deliver logical, sensible, and wise decisions that customers can implement. It would ultimately lead to quick problem resolution and an increased customer satisfaction.
-
Legal Document Analysis and Summarization - In the legal domain, LLMs can be trained to break down complex legal documents into small steps, starting from analysing documents, identifying risks, and logically summarizing the most essential sections. This structured approach leads to detailed analysis and the generation of concise summaries as per the legal requirements. Thus, Chain of thought prompting is responsible for making the legal content simple to review, understand, and make decisions for tasks like legal research, contract management, and compliance work.
CONCLUSION
From the above one can see that there are pros and cons to this new generation of transformers in terms of accuracy , response times , Api costs etc. however with the progression of time , ever improving magnitude and scope of data warehouses , and advancements in the realm of AI , the pros will certainly outweigh the cons. These models seem to be a glimpse into what could be in store for us and are in my opinion the way forward in the realm of AI.
REFERENCES
https://www.openxcell.com/blog/chain-of-thought-prompting/
https://www.techtarget.com/whatis/feature/OpenAI-o1-explained-Everything-you-need-to-know
Written By

Anmol Salvi
April 22, 2025



